Dictionaries and Sets
These notes are based on Fluent Python. Most of the content is summarized from the book, with a small portion being the author's own understanding. The notes were converted from Jupyter to Markdown; the original Jupyter notebook is in this repo.
General mapping types
The collections.abc module provides two abstract base classes, Mapping and MutableMapping. They define the formal interface for dict and other mapping-like types.
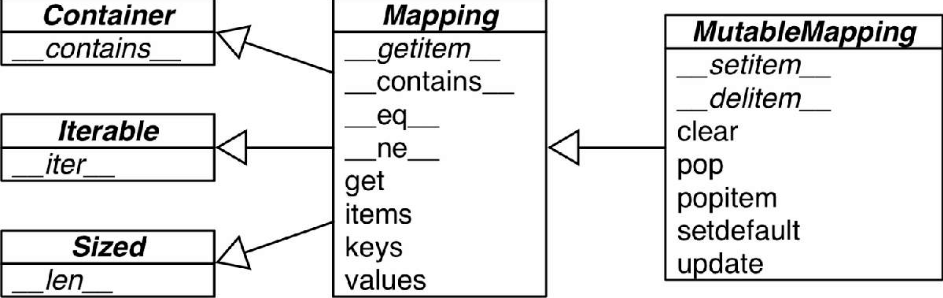
All mapping types in the standard library are implemented on top of dict. Because of this, they share a common limitation: only hashable types can be used as keys in these mappings (this requirement applies only to keys; values do not need to be hashable).
If an object is hashable, its hash value must remain constant during its lifetime, and it must implement the __hash__() method. A hashable object must also implement __eq__() so that it can be compared with other keys. If two hashable objects are equal, then their hash values must be the same.
- Atomic immutable types (
str,bytes, and numeric types) are all hashable.frozensetis also hashable, because by definition it can only contain hashable elements. - A tuple is hashable only if all of its elements are hashable.
In general, instances of user-defined classes are hashable by default, and their hash values are derived from the result of the id() function. This means such objects are all unequal to each other by default. If a class implements __eq__ and that method depends on the internal state of the object, then the object is hashable only if all of that internal state is immutable.
tt = (1, 2, (30, 40))
hash(tt)tl = (1, 2, [30, 40])
hash(tl)Raises:
TypeError: unhashable type: 'list'tf = (1, 2, frozenset([30, 40]))
hash(tf)Dictionaries provide multiple construction methods
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict({'three': 3, 'one': 1, 'two': 2})
e = dict([('two', 2), ('one', 1), ('three', 3)])
a == b == c == d == e# You can also build new dicts with dict comprehensions
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States'),
(62, 'Indonesia'),
(55, 'Brazil'),
(92, 'Pakistan'),
(880, 'Bangladesh'),
(234, 'Nigeria'),
(7, 'Russia'),
(81, 'Japan'),
]
country_code = {country: code for code, country in DIAL_CODES}
country_code{code: country.upper() for country, code in country_code.items() if code < 66 }Common dictionary methods:
| Method | Description |
|---|---|
dict.clear() | Remove all items from the dictionary |
dict.copy() | Return a shallow copy of the dictionary |
dict.fromkeys(seq[, val]) | Return a new dict with keys from seq and value val for all keys |
dict.get(key[, default]) | Return the value for key if present, otherwise return default |
dict.items() | Return a new view of the dictionary's key-value pairs |
dict.keys() | Return a new view of the dictionary's keys |
dict.pop(key[, default]) | Remove and return the value for key if present; otherwise return default |
dict.popitem() | Remove and return a key-value pair from the dictionary (for compatibility, returns the last inserted item) |
dict.setdefault(key[, default]) | If key is in the dict, return its value; if not, insert key with default and return default |
dict.update([other]) | Update the dictionary from another mapping or iterable of key-value pairs |
dict.values() | Return a new view of the dictionary's values |
You can use setdefault to handle missing keys.
Sometimes, even when a key is not present in a mapping, it is convenient to get a default value when reading it. There are two ways to achieve this:
- Use
collections.defaultdictinstead of a plaindict. - Define a
dictsubclass and implement the__missing__method.
import collections
index = collections.defaultdict(list)
index['unknown word']If a class inherits from dict and provides a __missing__ method, then when __getitem__ is called with a missing key, Python automatically calls __missing__ instead of raising KeyError.
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys([]) or str(key) in self.keys([])Variants of dict
collections.OrderedDict: preserves insertion order, so key iteration order is always predictable.collections.ChainMap: groups multiple mapping objects so that key lookups search them one by one as if they were a single mapping.collections.Counter: a mapping that stores integer counts for keys. Each update increments the counter. This is useful for counting hashable objects and is also known as a bag or multiset in other languages.collections.UserDict: a pure-Python implementation that wraps a realdict. It inherits fromcollections.MutableMapping, and is designed as a convenient base class for writing custom mapping types.
For creating custom mapping types, it is usually more convenient to subclass
UserDictthandict. A key reason is that the built-indictsometimes takes internal shortcuts in its method implementations, which can force you to override more methods than expected in subclasses.UserDictavoids these problems.
# This mapping converts all keys to strings for add/update/lookup operations
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = itemBecause UserDict inherits from MutableMapping, all remaining mapping methods of StrKeyDict are inherited from UserDict, MutableMapping, and Mapping. The ultimate base class Mapping is an abstract base class (ABC), but it still provides several useful concrete methods.
Two such methods are particularly worth noting:
MutableMapping.update: This method can be used directly. It is also used inside__init__so that the constructor can accept various forms of input (other mappings, iterables of(key, value)pairs, and keyword arguments). Internally it usesself[key] = valueto add new items, which in turn invokes the custom__setitem__method.This is one reason to subclass
UserDictinstead ofdict:dictmight bypass overridden methods in some internal operations.Mapping.get: Called inside__getitem__to provide a default value for missing keys. Internally it is implemented roughly asself[key] if key in self else default, which again relies on the custom__getitem__implementation.
Immutable mapping types
Starting from Python 3.3, the types module provides MappingProxyType, which creates a read-only view of a mapping. If you pass a mapping to MappingProxyType, it returns a dynamic, read-only view of that mapping. "Dynamic" means that changes to the original mapping are visible through the view, but the view itself cannot be used to modify the underlying data.
from types import MappingProxyType
d = {1: 'A'}
d_proxy = MappingProxyType(d)
d_proxyd_proxy[1]d_proxy[2] = 'X' # raises TypeError# But you can still modify the original mapping
d[2] = 'B'
d_proxySet theory
Conceptually, a set is a collection of unique objects. Because of this, sets are often used for deduplication.
Set elements must be hashable. The
settype itself is not hashable, butfrozensetis. Therefore, you can create asetcontaining multiple distinctfrozensetobjects.
l = ['spam', 'spam', 'eggs', 'spam']
set(l)list(set(l))Besides uniqueness, sets also implement many basic infix operators. Given two sets a and b:
a | breturns their union,a & breturns their intersection,a - breturns the difference.
Except for the empty set, set literals such as {1}, {1, 2}, etc. look exactly like their mathematical form. The empty set must be written as set().
Literals such as {1, 2, 3} are faster and more readable than set([1, 2, 3]). The latter is slower because Python must first look up the set constructor by name, then build a list, and finally pass that list to the constructor.
# Use dis.dis (the disassembler) to compare bytecode of the two approaches
from dis import dis
dis('{1}')dis('set([1])')Set comprehensions:
from unicodedata import name
{chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')}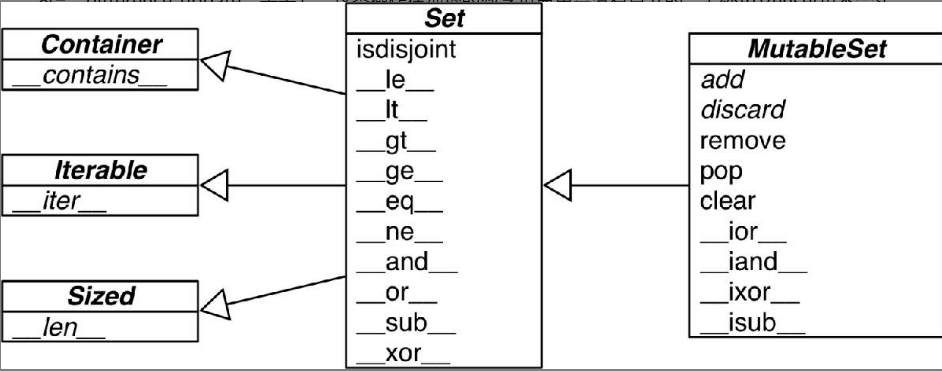
Common set operations:
| Operation | Description |
|---|---|
set1.union(set2) | Return a new set with elements from both set1 and set2 |
set1.intersection(set2) | Return a new set with elements common to set1 and set2 |
set1.difference(set2) | Return a new set with elements in set1 but not in set2 |
set1.symmetric_difference(set2) | Return a new set with elements in either set but not both |
set1.issubset(set2) | Return True if set1 is a subset of set2, otherwise False |
set1.issuperset(set2) | Return True if set1 is a superset of set2, otherwise False |
set1.isdisjoint(set2) | Return True if set1 and set2 have no elements in common, otherwise False |
set1.add(elem) | Add element elem to set1 |
set1.remove(elem) | Remove elem from set1; raise an error if elem is not present |
set1.discard(elem) | Remove elem from set1 if present; do nothing if not present |
set1.pop() | Remove and return an arbitrary element from set1; raise an error if the set is empty |
set1.clear() | Remove all elements from set1 |
Under the hood of dict and set
A benchmark of using the in operator to search for 1000 elements in dictionaries of five different sizes:
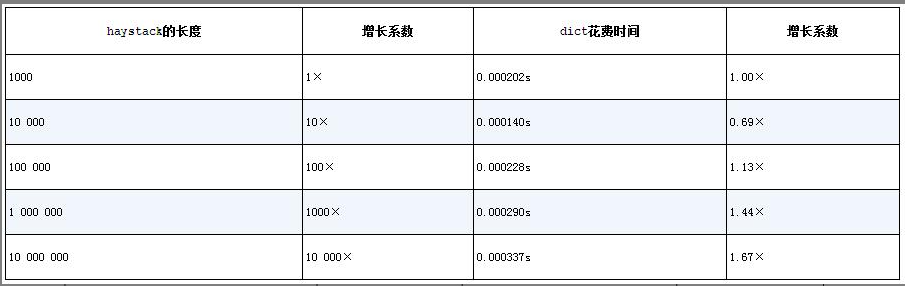
On that particular machine, searching for 1000 floats among 1000 dictionary keys took about 0.000202 seconds. Running the same search on a dictionary with 10,000,000 elements took only about 0.000337 seconds.
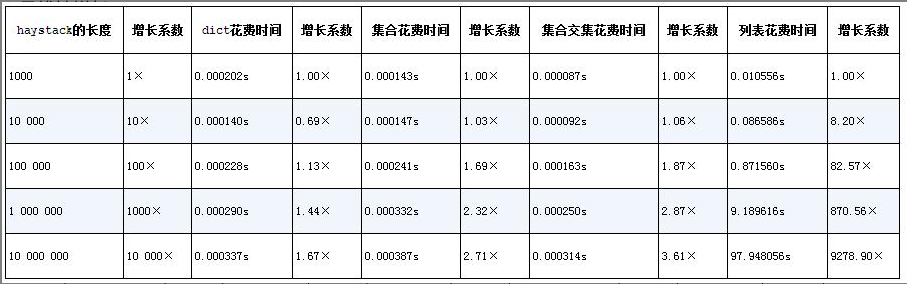
Adding lists into the benchmark for comparison:
Internal structure of a hash table: A hash table is essentially a sparse array (an array with empty slots). In standard data structure textbooks, each slot in a hash table is usually called a bucket. In Python's dict hash table, each key-value pair occupies one bucket. Each bucket holds a reference to the key and a reference to the value. Because all buckets have the same size, they can be accessed by an offset.
Python tries to keep roughly one-third of the buckets empty. When the table becomes too full, it is resized and all entries are copied into a larger table.
To put an object into a hash table, Python first computes the hash value of the key. In Python, this is done with the hash() function.
Hash values and equality
The built-in hash() function works for all built-in types. For instances of user-defined classes, hash() calls their __hash__ method. If two objects compare equal, their hash values must also be equal; otherwise hash tables will not function correctly. For example, since 1 == 1.0 is True, it must also be the case that hash(1) == hash(1.0), even though the internal representations of an integer and a float are completely different.
To serve as hash table indexes, hash values should be well-distributed over the index space. Ideally, the more similar two unequal objects are, the more different their hash values should be.
Starting from Python 3.3, the hash values of
str,bytes, anddatetimeobjects are salted with a random value. The salt is a process-wide constant, but a new random salt is generated every time the Python interpreter starts. This is a security measure to mitigate certain DoS attacks.
Hash table algorithm
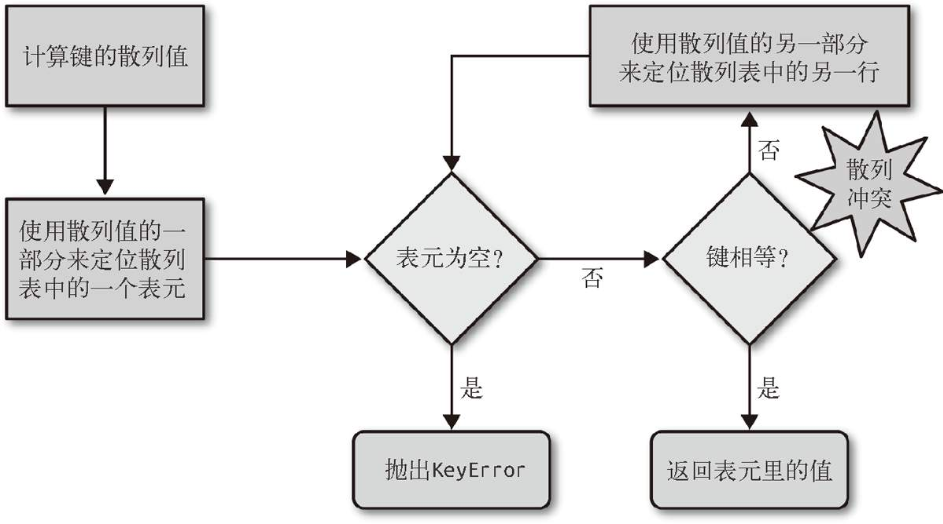
- To retrieve
my_dict[search_key], Python first computeshash(search_key), then uses the lower bits of the hash value as an offset into the hash table (the number of bits used depends on the table size). - If the bucket at that offset is empty, Python raises
KeyError. - If the bucket is not empty, it contains a
(found_key, found_value)pair. Python then checks whethersearch_key == found_key. If so, it returnsfound_value. - If
search_keyandfound_keyare not equal, this is a hash collision. Python then probes other locations in the table according to its collision resolution strategy until it finds either the key or an empty bucket. - When inserting a new item, Python may decide to resize the hash table if it becomes too full. Resizing increases the table size, and therefore the number of bits used from the hash value, which helps reduce the likelihood of collisions.
Although this algorithm may look expensive, in practice-even with millions of items-most lookups experience no collisions, and on average there may be just one or two collisions per lookup. Even in unlucky cases the number of collisions is usually very small.
Strengths and limitations of dict/set
1. Keys must be hashable
A hashable object must satisfy all of the following:
- Support the
hash()function and provide an unchanging hash value over its lifetime. - Support equality comparison via
__eq__(). - If
a == bisTrue, thenhash(a) == hash(b)must also beTrue.
All user-defined objects are hashable by default because their hash values are derived from id(), and by default they are all unequal.
2. Dictionaries have high memory overhead
Because dictionaries use hash tables, and hash tables must be sparse, dictionaries are not memory-efficient.
If you need to store a very large number of records, it is often better to use a list of tuples or namedtuple instances, rather than a list of dictionaries in a JSON-like style. Tuples save space for two reasons: you avoid the hash table overhead, and you do not need to store field names with every record.
3. Key lookup is fast
dict is a classic space-for-time trade-off: dictionaries use more memory, but they provide very fast access times that are almost independent of the number of stored items-as long as the dictionary fits in memory.
4. Key order depends on insertion order
When inserting new keys, if a hash collision occurs, Python might store the new key in a different location than where it would naturally go. As a result, two dictionaries created from lists of key-value pairs with different insertion orders, such as dict([(key1, value1), (key2, value2)]) and dict([(key2, value2), (key1, value1)]), will compare equal, but the internal order of their keys may differ if collisions occurred during insertion.
In contrast, consider PHP. The PHP manual describes arrays as follows: "An array in PHP is actually an ordered map. A map is a type that associates values to keys. This type is optimized for several different uses; it can be treated as an array, list (vector), hash table (map implementation), dictionary, collection, stack, queue, and more."
It is hard to imagine the complexity and overhead of implementing something that mixes lists and ordered dictionaries in this way.
PHP and Ruby borrowed their hash literal syntax from Perl, using => between keys and values. JavaScript borrowed its syntax from Python, using :. JSON, derived from JavaScript, is essentially a subset of Python's literal syntax. Other than the spelling differences in the literals true, false, and null, JSON is fully compatible with Python's syntax.